Waarom heeft de Plagiaat Checker mijn gekopieerde fragment niet gevonden?
Er zijn vijf mogelijke redenen waarom de Plagiaat Checker jouw fragment niet herkend heeft:
Je hebt het fragment correct geparafraseerd
Zodra je de originele tekst netjes geparafraseerd hebt door de woorden en woordvolgorde aan te passen, zal het fragment niet herkend worden door de Plagiaat Checker. Je kunt dit makkelijk testen door een zin via Google op te zoeken: zet de zin tussen dubbele aanhalingstekens en plaats deze in de zoekbalk. Als er niets gevonden wordt, zit je goed. Als er wel iets gevonden wordt, maar de Plagiaat Checker heeft je tekst niet gemarkeerd, zit de bron waarschijnlijk niet in onze database.
De instelling voor “kleine overeenkomsten” in je document staat te hoog ingesteld
Standaard toont het plagiaatrapport overeenkomsten van 9 woorden of meer. Als het fragment dat je gekopieerd hebt minder woorden bevat, wordt het niet herkend. Je kunt dit aantal handmatig aanpassen.
Je hebt het originele fragment vertaald
De Plagiaat Checker zoekt naar overeenkomsten. Als je het originele fragment vertaald hebt is er geen overeenkomst en wordt het fragment dus niet herkend.
Je bestand is niet leesbaar
Als je een pdf-bestand geüpload hebt, kan het zijn dat je bestand niet leesbaar is of naar een afbeelding is geconverteerd, in plaats van tekst. Hierdoor zou het kunnen dat er geen overeenkomsten getoond worden. Je kunt dit testen door de tekst in je document in een tekstverwerker (zoals Word of Kladblok) te plakken. Als de tekstverwerker dezelfde tekst toont, kan onze Plagiaat Checker het bestand ook lezen.
Veelgestelde vragen: Plagiaat Checker
- Kan je Scribbrs Plagiaat Checker gratis gebruiken?
-
Ja, Scribbr biedt een beperkte gratis versie van de Plagiaat Checker aan. Deze gebruikt toonaangevende plagiaatdetectietechnologie en heeft toegang tot de grootste database.
- Hoe nauwkeurig is de Scribbr Plagiaat Checker?
-
Uitgebreid onderzoek bewijst dat Scribbrs Plagiaat Checker één van de meest nauwkeurige plagiaatcontroles op de markt is.
De software detecteert alles van exacte woordovereenkomsten tot het verwisselen van synoniemen. De plagiaat checker heeft ook toegang tot een volledig scala aan brontypen, waaronder open en beperkt toegankelijke tijdschriftartikelen, scripties en proefschriften, websites, pdfs en nieuwsartikelen.
- Kan ik twee documenten vergelijken op plagiaat met Scribbrs gratis Plagiaat Checker?
-
Online plagiaatcheckers hebben alleen toegang tot openbare databases, en daarom kun je met die software niet twee documenten vergelijken om plagiaat te detecteren.
Twee documenten vergelijken op plagiaat met de Zelfplagiaat Checker
Scribbr biedt naast een reguliere, gratis Plagiaat Checker ook een Zelfplagiaat Checker waarbij je je eigen bronnen kunt uploaden, zoals een oude opdracht voor een ander vak, een scriptie van een studiegenoot, en andere bronnen.
Deze bronnen worden vergeleken met je tekst, waarna je een rapport ontvangt waarin de overeenkomsten gemarkeerd zijn.


Zo kun je voor iedere markering vaststellen of er sprake is van onbedoeld (zelf)plagiaat en kun je ontbrekende verwijzingen en aanhalingstekens toevoegen voordat je je document officieel inlevert.
- Welke technologie gebruikt Scribbrs gratis Plagiaat Checker?
-
Scribbr gebruikt geavanceerde plagiaatdetectietechnologie die vergelijkbaar is met de software die door de meeste universiteiten en uitgevers wordt gebruikt, waardoor je verzekerd bent van dezelfde of zeer vergelijkbare resultaten.
De add-on AI Detector wordt aangestuurd door Scribbrs eigen software en is in staat om teksten gegenereerd door ChatGPT, Gemini en andere AI-tools met hoge nauwkeurigheid te detecteren.
- Wat is het verschil tussen de gratis en premium plagiaat checker?
-
Het gratis plagiaatrapport vertelt je of je werk mogelijk plagiaat bevat. Het premiumrapport geeft je de middelen die je nodig hebt om je werk plagiaatvrij te maken.
Gratis rapport Premium rapport (vanaf €14,95) - Risicobeoordeling
- Top 5 overeenkomende bronnen
- Nauwkeurig plagiaatpercentage
- Complete lijst van overeenkomende bronnen
- Documentweergave om snel overeenkomsten te bekijken
- Zij-aan-zij vergelijking met de originele tekst
- Upload ongepubliceerde documenten
- Ondersteuning via de chat
- Wat betekent een “hoog” of “matig” risico op plagiaat?
-
De gratis plagiaatcontrole van Scribbr schat het risico op plagiaat in door het percentage tekst in je document te berekenen dat lijkt op andere bronnen.
Een matig of hoog plagiaatrisico betekent dat de plagiaatsoftware verschillende overeenkomsten heeft ontdekt die de moeite waard zijn om te bekijken.
Merk op dat overeenkomsten niet noodzakelijkerwijs plagiaat zijn. Je moet zelf beslissen of je tekst moet worden herzien of geciteerd.
- Waarom zijn overeenkomsten in verschillende kleuren gemarkeerd?
-
Scribbrs gratis Plagiaat Checker markeert overeenkomsten in je document, zodat je ze snel en gemakkelijk kunt bekijken. Elke kleur komt overeen met een bron in je Bronnenoverzicht aan de rechterkant van je rapport.
- Ik herken een bron die de plagiaat checker heeft gevonden niet. Wat nu?
-
Informatie is vaak op meer dan één plaats te vinden. Daarom kunnen andere bronnen die dezelfde informatie aanhalen als die jij hebt gebruikt, opduiken in je Bronnenoverzicht.
Het gaat erom dat je de bron van de informatie vermeldt. Probeer daarom de oorspronkelijke bron te vinden. Als je die niet kunt vinden, kun je het beste de bron vermelden waar je de informatie hebt gevonden.
- Hoe kan ik irrelevante overeenkomsten van mijn plagiaatpercentage uitsluiten?
-

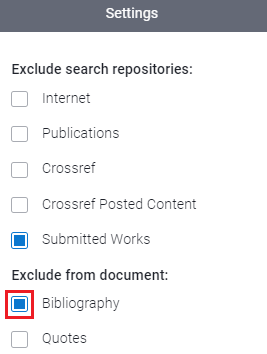
Soms vindt de Scribbr Plagiaat Checker overeenkomsten die geen plagiaat zijn, zoals bronvermeldingen en citaten met een correcte bronvermelding. Je kunt deze overeenkomsten uitsluiten van je totale plagiaatpercentage.Overeenkomsten uitsluiten:
Stap 1: Open je plagiaatrapport.
Stap 2: Klik op de gemarkeerde overeenkomst die je wilt uitsluiten.
Stap 3: Klik op de “Bron uitsluiten” knop.De bron is nu uitgesloten van je totale plagiaatpercentage.
Het gebeurt soms dat je plagiaatrapport een foutmelding toont als je meerdere overeenkomsten hebt uitgesloten. Helaas is dit een probleem dat we momenteel niet op kunnen lossen.
Als dit probleem zich voordoet kun je simpelweg alle irrelevante overeenkomsten tellen, en de totale score van je plagiaatpercentage aftrekken. Zo weet je toch wat je uiteindelijke percentage is.
- Wat kan ik doen als ik niet tevreden ben met het resultaat van de Plagiaat Checker?
-
Ben je niet tevreden met het resultaat van de Scribbr Plagiaat Checker? Of heb je moeilijkheden met je document? Lees hier wat je moet doen als….
- je je resultaat niet kan zien: Probeer het resultaat in Google Chrome te openen, of vraag een pdf-versie aan
- je een foutmelding in de koptekst van je document ziet staan: Geen zorgen, je kunt de foutmelding negeren.
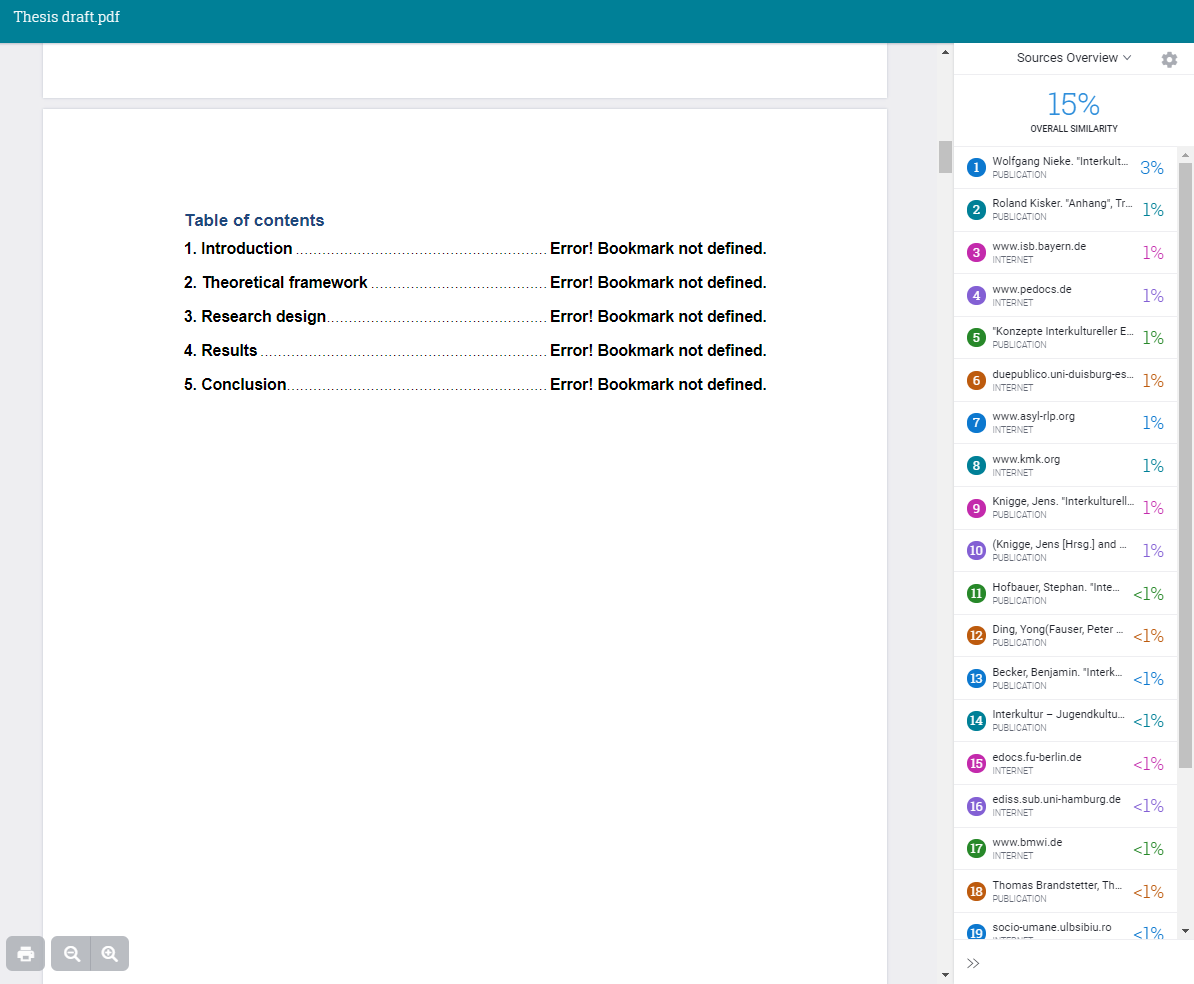
- je “Error! Bookmark not defined” in je inhoudsopgave ziet staan: Geen zorgen, dit heeft geen invloed op je resultaat.
- je niet tevreden bent met je plagiaatpercentage: Het plagiaatpercentage geeft aan welk percentage van je tekst door de software is gevonden in bronnen uit de uitgebreide database met meer dan 99 miljard webpagina’s en 8 miljoen publicaties. Dit betekent dat we je score niet aan kunnen passen. Echter, je kunt de overeenkomsten zelf verlagen door onze handleidingen over het interpreteren van je plagiaatrapport en het voorkomen van plagiaat te raadplegen. Het plagiaatpercentage van je ingezonden document zal dan een stuk lager zijn. Als je na de wijzigingen je nieuwe score wilt zien kun je een tweede check kopen.
- je niet 100% tevreden bent met onze dienst: Lees over onze 100% tevredenheidsgarantie en vul het formulier in. We nemen binnen 24 uur contact met je op.
- Hoe werkt het uitsluiten van kleine overeenkomsten in het plagiaatrapport?
-
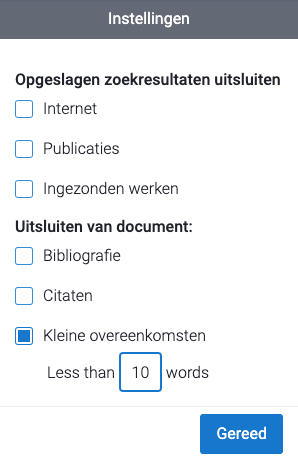
Het plagiaatrapport van de Plagiaat Checker toont standaard alleen overeenkomsten van 9 woorden of meer.

Je kunt zelf de minimale lengte van een overeenkomst wijzigen om kleine overeenkomsten van het plagiaatrapport uit te sluiten.
Welke minimale lengte voor overeenkomsten kan ik het best instellen?
De beste minimale lengte van overeenkomsten verschilt per document. Over het algemeen krijg je veel kleine overeenkomsten die waarschijnlijk geen plagiaat zijn als het minimum op 8 woorden of lager staat. Daarom is de standaardwaarde ingesteld op 9 woorden.
Echter, als je vindt dat je document veel kleine overeenkomsten bevat die geen plagiaat zijn (zoals deze), kun je de minimale lengte wijzigen naar 10 of 11 woorden.
Pas wel op met het verhogen van de minimale lengte; dit verbergt mogelijk plagiaat in je rapport.
Hoe kan ik de instellingen voor het uitsluiten van kleine overeenkomsten aanpassen?
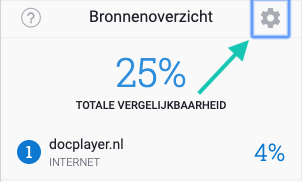
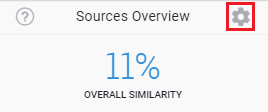
1. Klik op het tandwielpictogram rechtsboven in het plagiaatrapport.

2. Vul de gewenste minimale lengte van een overeenkomst in.

3. Klik op “Gereed” om terug te gaan naar het bronnenoverzicht.
Wanneer moet ik de instellingen voor het uitsluiten van kleine overeenkomsten wijzigen?
In de meeste gevallen is het niet nodig om de standaardinstellingen te wijzigen. Als je echter meer controle wil over de overeenkomsten die in je rapport worden weergegeven en je denkt dat de meeste kleine overeenkomsten niet relevant zijn, kun je de waarde verhogen.
Pas wel op met het verhogen van deze waarde. Plagiaat kan hierdoor ook worden verborgen. We raden je af de waarde te verhogen.
Wat gebeurt er als je de waarde verlaagt?
Als je de waarde verlaagt, worden kortere overeenkomsten in het rapport ook getoond. Dit betekent dat je meer overeenkomsten en een hoger percentage plagiaat zult zien.
De meeste van deze extra overeenkomsten zijn waarschijnlijk echter geen plagiaat. Korte overeenkomsten zijn namelijk vaak het resultaat van veelvoorkomende zinnen die in verschillende bronnen voorkomen. We raden je daarom niet aan de waarde te verlagen.
Wat gebeurt er als je de waarde verhoogt?
Als je de waarde verhoogt, worden alleen langere overeenkomsten in het rapport getoond. Dit betekent dat je een lager percentage overeenkomsten zult zien.
Omdat de fragmenten langer zijn, is de kans groter dat de overeenkomsten die je nu ziet plagiaat zijn.
- Ik heb de Scribbr Plagiaat Checker afgenomen in combinatie met de nakijkservice. Wanneer kan ik de Plagiaat Checker het beste starten?
-
Als je de (gratis) Plagiaat Checker hebt afgenomen en je je scriptie hebt laten nakijken, kun je deze check starten wanneer je wil.
Scribbr raadt je echter aan om de Plagiaat Checker pas te gebruiken nadat je het nagekeken document hebt ontvangen en alle wijzigingen hebt verwerkt. Dan kun je de meest recente versie van je scriptie uploaden en voorkom je dat je handmatig aanpassingen moet doen in je nieuwste versie.
- Ik heb het verkeerde document geüpload in de Scribbr Plagiaat Checker. Kan ik gratis een nieuwe check krijgen?
-
Als je per ongeluk het verkeerde document hebt geüpload in de Plagiaat Checker kan Scribbr de kosten van deze check niet terugbetalen en ook geen korting geven op een nieuwe check. De check start automatisch na de betaling, waardoor we je document niet meer kunnen vervangen.
- Waarom kan ik de resultaten van mijn plagiaatcheck niet zien?
-
Als je de resultaten van de Plagiaat Checker niet kunt zien, zijn er twee opties om alsnog toegang tot je resultaten te krijgen.
1. Gebruik je Google Chrome?
Als je Google Chrome gebruikt, treedt deze fout vaak niet meer op. Probeer daarom eerst de resultaten van de plagiaatcheck met Google Chrome te openen. Als je deze browser al gebruikt of als deze oplossing niet werkt, kijk dan bij optie 2.
2. Neem contact op met support om een pdf-versie van je bestand te ontvangen
Als optie 1 niet werkt, kun je contact opnemen met ons supportteam via de chat of via e-mail met het verzoek een pdf-versie van de resultaten op te sturen. Zo kun je alsnog met de resultaten aan de slag!
- Waarom zie ik “Error! Bookmark not defined” in mijn inhoudsopgave?
-
Geen zorgen! Deze foutmelding beïnvloedt de nauwkeurigheid van jouw Plagiaatcheck niet.
Als je een automatische inhoudsopgave en/of lijst van tabellen en figuren hebt, is het mogelijk dat je een foutmelding ziet in plaats van de paginanummers. De foutmelding ziet er waarschijnlijk uit als “Error! Bookmark not defined”.
Helaas is dit een probleem dat we niet kunnen oplossen. Het kan zijn dat de Scribbr gratis Plagiaat Checker deze foutmeldingen als overeenkomsten markeert. Je kunt deze overeenkomsten negeren.

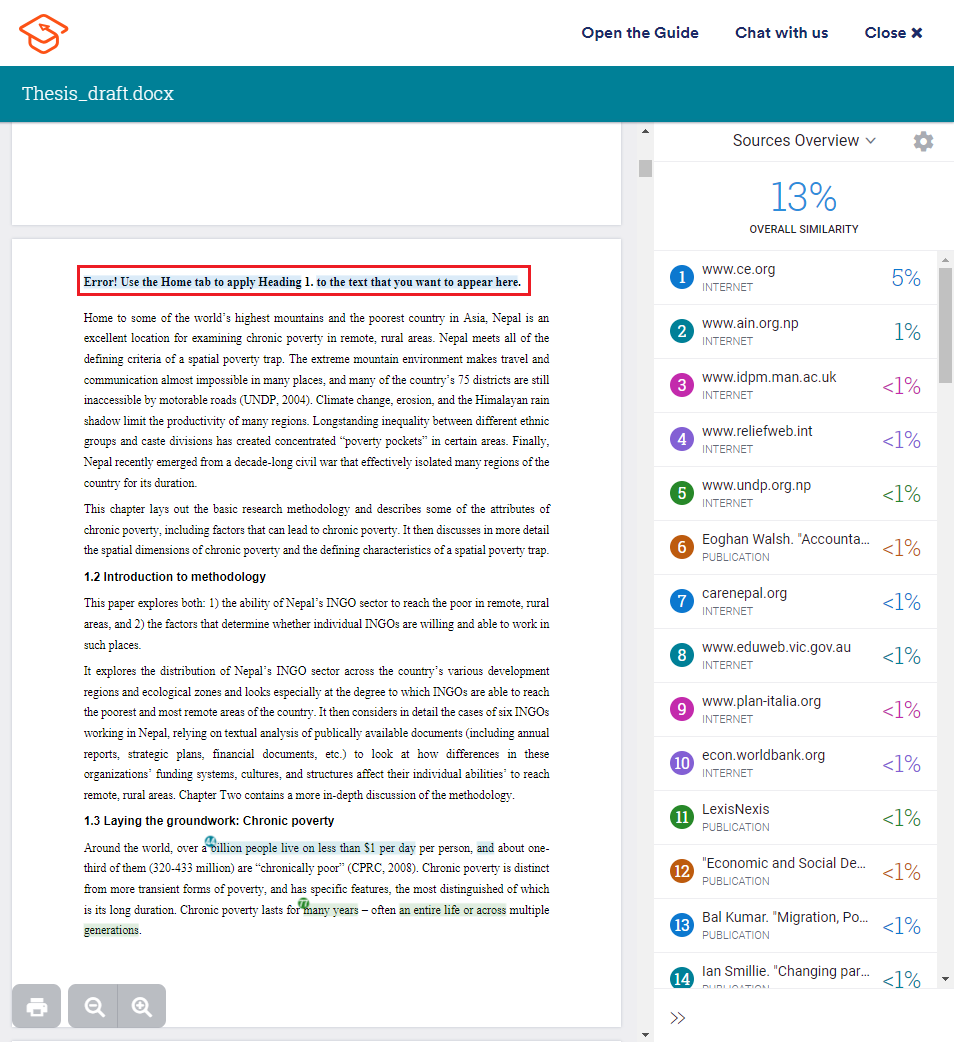
- Waarom staat er een foutmelding in de titels van mijn document?
-
Geen zorgen! Deze foutmelding beïnvloedt de nauwkeurigheid van jouw plagiaatcheck niet.
Als je de titel van je hoofdstuk in de koptekst hebt toegevoegd, kan dit resulteren in een foutmelding bij het verwerken van de plagiaatcheck.

In plaats van de hoofdstuktitel zie je een tekst die vergelijkbaar is met het screenshot hierboven. Helaas kunnen we dit niet oplossen.
De gratis Plagiaat Checker ziet deze foutmelding in sommige gevallen als een overeenkomst. Je kunt deze overeenkomsten negeren.
- Wat moet ik doen als het plagiaatpercentage 0% is?
-
Een plagiaatpercentage van 0% betekent dat er geen overeenkomsten zijn gevonden door de Scribbr gratis Plagiaat Checker.
Gefeliciteerd! Dit is erg zeldzaam: dit zien we maar bij 1 op de 150 studenten.
- Hoe laag moet het plagiaatpercentage zijn?
-
Je document mag helemaal geen plagiaat bevatten. Een score van 1% is dus eigenlijk al te hoog.
Alleen zijn in de praktijk niet alle gevonden overeenkomsten ook daadwerkelijk plagiaat. De Scribbr gratis Plagiaat Checker markeert soms ook:
- Geciteerde fragmenten
- Referentielijsten
- Standaardzinnen die vaak in scripties gebruikt worden
Daarnaast zijn ook overeenkomsten in bepaalde hoofdstukken in je scriptie minder belangrijk.
Zelfs met een score van 1% moet je voor de zekerheid elke gevonden overeenkomst bekijken en verbeteren waar nodig.
Wat moet ik doen met een gevonden overeenkomst?
- Wat betekent het plagiaatpercentage?
-
Het plagiaatpercentage geeft aan welk percentage van jouw document is gevonden in de plagiaatdatabase.
Een percentage van 15% betekent dat 15% van jouw document overeenkomt met de plagiaatdatabase. Dit betekent nog niet meteen dat je ook plagiaat hebt gepleegd.
Zo zijn in de praktijk niet alle gevonden overeenkomsten ook daadwerkelijk plagiaat. Onze gratis Plagiaat Checker markeert soms ook:
- Geciteerde fragmenten
- Referentielijsten
- Standaardzinnen die vaak in scripties gebruikt worden
Iedere overeenkomst die in jouw document wordt gevonden moet je daarom analyseren.
Wat is een goed percentage? Hoe verbeter ik overeenkomsten?
- Wat moet ik doen met een gevonden overeenkomst?
-
Bekijk elke gevonden overeenkomst in het rapport van Scribbrs gratis Plagiaat Checker. Per overeenkomst moet je zelf bepalen of dit plagiaat is of niet.
Met andere woorden: heb je de gevonden overeenkomst inderdaad gekopieerd uit de gevonden bron? Dan is het plagiaat.
- Bekijk de gevonden overeenkomst. Heb je het fragment gekopieerd?
- Herschrijf de gevonden overeenkomst. Zorg dat je correct parafraseert (in eigen woorden opschrijven) of citeert. Vergeet niet om een bronvermelding toe te voegen.
Stappenplan om gevonden overeenkomsten te verbeteren
- Kan ik mijn document meerdere keren op plagiaat controleren?
-
De Scribbr Plagiaat Checker scant je document per upload één keer. We raden je aan om de twee simpele stappen hieronder te volgen, zodat je ieder stukje tekst dat mogelijk plagiaat is grondig kunt controleren.
Door deze stappen te volgen, kun je er zeker van zijn dat je alle plagiaat uit je document verwijderd hebt. Het is daarom niet nodig om je document nogmaals in de Plagiaat Checker te uploaden. Als je toch een tweede of derde check wilt doen, kun je deze tegen het reguliere tarief kopen.
Stap 1: Controleer elke overeenkomst die de Plagiaat Checker gemarkeerd heeft
Bedenk of de overeenkomst logisch is:
- Is de overeenkomst een citaat met correcte bronvermelding, onderdeel van je literatuurlijst of een algemeen stukje tekst dat niet met een specifieke bron te maken heeft? Dan hoef je niets aan te passen. Je kunt de overeenkomst eenvoudig uitsluiten van je totale score.
- Is de overeenkomst een woordgroep of zin die je gekopieerd hebt uit een bron zonder de bron te vermelden? Ga dan naar stap 2.
Stap 2: Pas ieder mogelijk geplagieerd stuk tekst aan
Er zijn twee manieren waarop je een overeenkomst kunt aanpassen.
- Parafraseren: Herschrijf de tekst in je eigen woorden. Let op: simpelweg de woordvolgorde veranderen of een paar woorden door synoniemen vervangen is niet genoeg om plagiaat te verwijderen. Je kunt de tekst het beste helemaal opnieuw schrijven, zodat je zeker weet dat je zinsbouw origineel is.
- Citeren: Als je de exacte woorden van de auteur wilt gebruiken, plaats de tekst dan tussen aanhalingstekens (“).
Of je nu parafraseert of citeert, bronvermelding is altijd vereist. Heb je meer hulp nodig bij het controleren en verbeteren van je overeenkomsten? Kijk dan in onze handleiding.
- Met welke databases wordt mijn document vergeleken?
-
De Scribbr Plagiaat Checker vergelijkt de inhoud van je document, met de grootste en snelst groeiende database ter wereld:
- 99,3 miljard huidige en historische webpagina’s.
- 8 miljoen wetenschappelijke artikelen en boeken van meer dan 1.700 uitgevers zoals Elsevier, Springer en Wiley-Blackwell.
- Wat doe ik met een citaat dat gevonden is door de plagiaatcheck?
-
Het komt soms voor dat een citaat wordt gevonden door de Plagiaat Checker.
Een citaat dat door de check wordt gevonden is geen plagiaat. Het is daarbij wel van belang dat je een bronvermelding aan het citaat hebt toegevoegd. Hieronder volgen in het kort de eisen voor een citaat volgens de APA-regels.
Citaat van minder dan 40 woorden
Bij het citeren van een tekst van minder dan 40 woorden maak je gebruik van dubbele aanhalingstekens direct voor en direct achter het citaat. Daarnaast vermeld je de auteur, het jaartal en een paginanummer.
Voorbeeld citaat minder dan 40 woorden
Zo kwam in het interview naar voren: “Het Haagse accent van Willy is erg fijn om in te spreken” (Van de Pavert, 2015, p. 2).Citaat van meer dan 40 woorden
Bij een citaat van meer dan 40 woorden moet je de tekst in een apart blok zetten en dit blok laten inspringen. Je gebruikt geen aanhalingstekens.
Voorbeeld citaat meer dan 40 woorden
Uit de conclusie komt het volgende naar voren:
Het blijkt dat consumenten het bezoeken van fysieke winkels als plezierig ervaren wanneer ze op zoek gaan naar hightech-producten. Zo plezierig zelfs dat consumenten ook niet online naar productinformatie op zoek gaan. Voor producten die rond het midden van het continuüm liggen, wordt alleen de daadwerkelijke aankoop als plezierig ervaren. (Swaen, 2009, p. 24)Zie het artikel over citeren volgens de APA-regels voor meer info.
- Waarom wordt een bron in mijn literatuurlijst als overeenkomst aangemerkt?
-
De Plagiaat Checker zoekt het internet en wetenschappelijke bronnen af naar overeenkomsten met jouw document. Omdat veel studenten op dezelfde manier hun bronnen opschrijven in de literatuurlijst (bijvoorbeeld volgens de APA-stijl) betekent dit dat de check vaak overeenkomsten vindt met deze bronnen.
Een bronvermelding die is gevonden door de Scribbr Plagiaat Checker is nooit plagiaat. Je hoeft dus niets met deze overeenkomst te doen.
Hoe je ervoor zorgt dat je literatuurlijst niet wordt meegenomen in de resultaten
Je kunt overeenkomsten uit je literatuurlijst niet laten meetellen in het resultaat van je Plagiaatcheck. Dit is bij sommige documenten echter niet mogelijk. Je kunt het op deze manier proberen:
Stap 1: open het resultaat van je Plagiaatcheck
Stap 2: klik op de instellingenknop onder ‘Sources overview’ (zie afbeelding hieronder)
Stap 3: kies voor de optie om je literatuurlijst niet mee te rekenen (zie afbeelding hieronder)
Stap 4: klik op ‘Done’

- Welke talen ondersteunt de Scribbr Plagiaat Checker?
-
De Scribbr Plagiaat Checker ondersteunt bijna alle Europese talen. De check ondersteunt:
- Nederlands
- Engels
- Duits
- Frans
- Spaans
- Portugees
- Italiaans
- Fins
- Zweeds
- Noors
- Deens
- Pools
- Russisch
- Turks
- Grieks
- Kroatisch
- Servisch
- Bosnisch
- Tsjechisch
- Arabisch
- Is het resultaat van de Scribbr Plagiaat Checker hetzelfde als op mijn school?
-
Scribbr gebruikt geavanceerde plagiaatdetectietechnologie die vergelijkbaar is met de software die door de meeste universiteiten en uitgevers wordt gebruikt, waardoor je verzekerd bent van dezelfde of zeer vergelijkbare resultaten.
Het enige verschil is dat je onderwijsinstelling het document mogelijk vergelijkt met eerder ingeleverde documenten uit een afgeschermde database. Scribbr heeft geen toegang tot deze privé-databases (net als alle andere plagiaatcheckers).
Gelukkig hebben we daar een oplossing voor! Voor dit soort situaties hebben we namelijk de Scribbr Zelfplagiaat Checker ontwikkeld. De Zelfplagiaat Checker zit inbegrepen bij je Plagiaat Checker order, zodat je jouw document gratis kunt vergelijken met met documenten die jij hebt gebruikt.
- Kunnen andere plagiaatcheckers of mijn docent mijn inzendingen bij Scribbr zien?
-
Je werk blijft privé. De documenten die je uploadt bij Scribbr worden niet gepubliceerd in een openbare database, dus geen enkele andere plagiaatchecker (inclusief die van universiteiten) kan ze zien.
- Hoelang duurt de Scribbr Plagiaat Checker?
-
De Plagiaat Checker duurt ongeveer 10 minuten. Voor documenten groter dan 25.000 woorden kan de check iets langer duren. Je krijgt dan een tijdsinschatting te zien op de orderpagina.
Zodra de check is afgerond krijg je van ons een e-mail.
- Welke bestandsformaten zijn geschikt voor de Scribbr Plagiaat Checker?
-
De volgende bestandsformaten zijn geschikt om een plagiaatcheck mee uit te voeren:
- doc
- docx
- odt
Het resultaat wordt niet beïnvloed door het bestandsformaat dat je kiest.
- Krijg ik een 100% overeenkomst bij mijn school als ik de Scribbr Plagiaat Checker gebruik?
-
Nee, je zult nooit een 100% overeenkomst krijgen, omdat de Scribbr Plagiaat Checker geen documenten in een openbare database opslaat.





{kind=link}