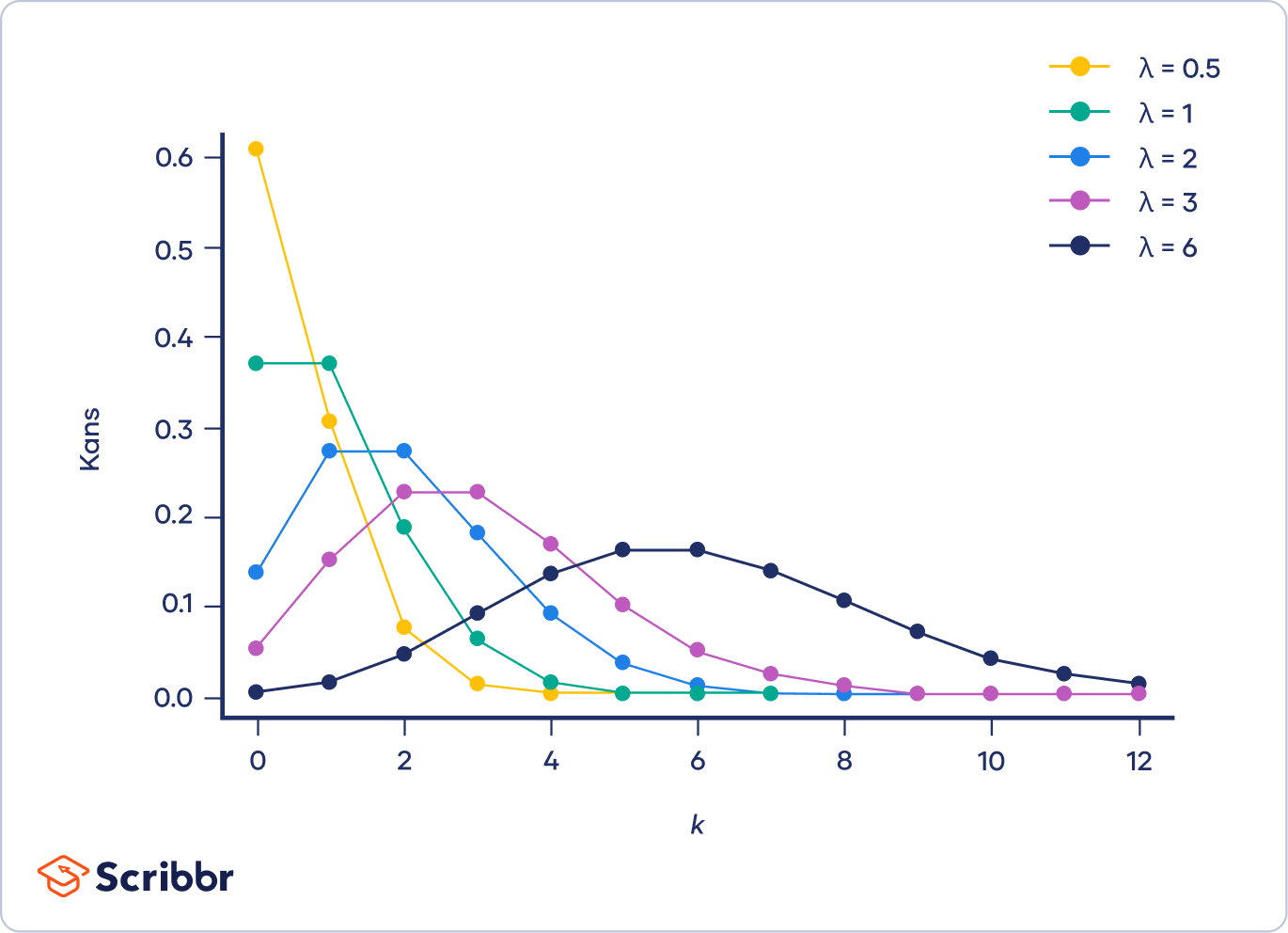
Een Poissonverdeling (Poisson distribution) is een discrete kansverdeling. De verdeling weergeeft de kans dat een gebeurtenis zich een bepaald aantal keren (k) binnen een bepaald tijds- of ruimte-interval voordoet.
De Poissonverdeling heeft slechts één parameter, λ (lambda), die het gemiddelde aantal gebeurtenissen representeert. De onderstaande grafiek toont voorbeelden van Poissonverdelingen met verschillende waarden van λ.
Gepubliceerd op
19 augustus 2022
door
Shaun Turney.
Bijgewerkt op
1 mei 2023.
Een systematische review (systematic review) is een soort review waarbij formele, herhaalbare methoden worden gebruikt om al het beschikbare bewijsmateriaal uit de bestaande literatuur te vinden, te selecteren en te synthetiseren.
In de review beantwoord je een duidelijk geformuleerde onderzoeksvraag en vermeld je expliciet de methoden die zijn gebruikt om tot het antwoord te komen.
Voorbeeld: Systematische review (systematic review)In 2008 publiceerden dr. Robert Boyle en zijn collega’s een systematische review in de Cochrane Database of Systematic Reviews.
Zij beantwoordden de vraag: “Wat is de effectiviteit van probiotica bij het verminderen van eczeemsymptomen en het verbeteren van de kwaliteit van leven bij patiënten met eczeem?”
Een probioticum is in deze context een gezondheidsproduct dat levende micro-organismen bevat en via de mond wordt ingenomen. Eczeem is een veel voorkomende huidaandoening die een rode, jeukende huid veroorzaakt.
De onderzoekers pasten systematische methoden toe om al het beschikbare bewijs uit de literatuur te vinden, te selecteren en the synthetiseren. Vervolgens beschreven ze deze methoden in detail in hun artikel. Op basis van het bewijsmateriaal concludeerden Boyle en zijn collega’s dat probiotica niet kunnen worden aanbevolen voor het verminderen van eczeemsymptomen of het verbeteren van de kwaliteit van leven bij patiënten met eczeem.
De t-tabel (t table) is een referentietabel met de kritieke waarden van t. De t-tabel wordt ook wel Student’s t-tabel, t-verdelingstabel, t-score tabel, t-waarde tabel, of t-test tabel genoemd.
Een kritieke waarde van t bepaalt de drempel voor significantie voor statistische toetsen en de boven- en ondergrens van betrouwbaarheidsintervallen voor schattingen. De t-tabel wordt meestal gebruikt:
Als je toetst of twee gemiddelden significant van elkaar verschillen (ongepaarde t-test, independent samples t test).
De kritieke waarden van t worden berekend aan de hand van de Student’s t-verdeling. Dit is de verdeling van teststatistiek t. Het is lastig om de kritieke waarden van t handmatig te berekenen. Daarom gebruiken de meeste mensen in plaats daarvan de t-tabel of computersoftware.
Gepubliceerd op
17 augustus 2022
door
Shaun Turney.
Bijgewerkt op
13 maart 2023.
De Pearson correlatiecoëfficiënt (Pearson correlation coefficient), aangeduid met r, is de meest gebruikelijke manier om een lineaire correlatie te meten. Het is een getal tussen de -1 en 1 dat de sterkte en de richting van het verband tussen twee variabelen meet.
Pearson correlatie coëfficiënt (r)
Soort correlatie
Interpretatie
Voorbeeld
Tussen 0 en 1
Positieve correlatie
Als één variabele verandert, verandert de andere variabele in dezelfde richting.
Lengte en gewicht van baby’s:
Hoe langer de baby, hoe zwaarder hun gewicht.
0
Geen correlatie
Er is geen verband tussen de variabelen.
Prijs van de auto en de breedte van de ruitenwissers:
De prijs van een auto houdt geen verband met de breedte van de ruitenwissers.
Tussen
0 en –1
Negatieve correlatie
Als één variabele verandert, verandert de andere variabele in de tegengestelde richting.
Gepubliceerd op
16 augustus 2022
door
Shaun Turney.
Bijgewerkt op
8 maart 2023.
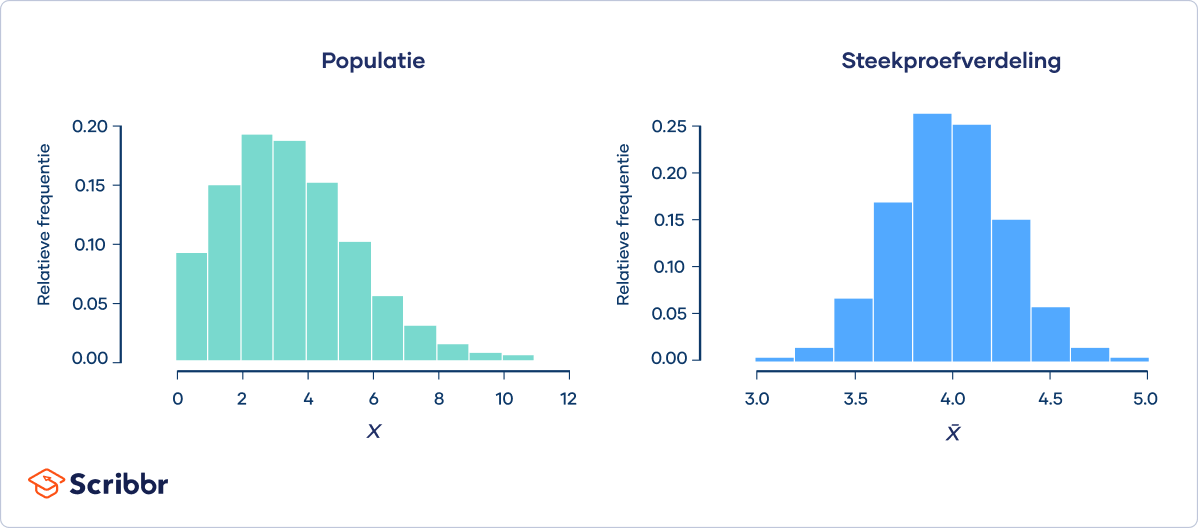
De centrale limietstelling (central limit theorem) stelt dat de gemiddelden van steekproeven altijd normaal verdeeld zullen zijn als je steekproeven van voldoende omvang neemt uit een populatie, zelfs als die populatie niet normaal verdeeld is.
Voorbeeld: Centrale limietstellingStel je voor dat een populatie een Poissonverdeling volgt (zie linkerplaatje). Je besluit 10.000 steekproeven te nemen uit de populatie. De steekproefgrootte voor elke steekproef is 50.
Op het rechterplaatje zie je dat de steekproefgemiddelden een normale verdeling volgen, zoals wordt voorspeld door de centrale limietstelling.
Gepubliceerd op
15 augustus 2022
door
Shaun Turney.
Bijgewerkt op
13 maart 2023.
Vrijheidsgraden (degrees of freedom), meestal aangeduid met df of , is het aantal onafhankelijke stukjes informatie dat wordt gebruikt om een statistiek te berekenen. Je berekent de vrijheidsgraden door het aantal beperkingen van de steekproefgrootte af te halen.
Vrijheidsgraden worden normaal gesproken tussen haakjes naast de teststatistiek vermeld, samen met de resultaten van de statistische test.
Voorbeeld: VrijheidsgradenStel dat je een willekeurige steekproef verzamelt van 10 Amerikaanse volwassenen en dat je hun dagelijkse calciuminname meet. Je gebruikt een eenzijdige t-toets (one sample t test) om te bepalen of de gemiddelde dagelijkse inname van Amerikaanse volwassenen gelijk is aan de aanbevolen hoeveelheid van 1000 mg.
De teststatistiek, t, heeft 9 vrijheidsgraden, want:
df = n – 1 (waarbij n = de steekproefgrootte)
df = 10 – 1
df = 9
Je berekent een t-waarde van 1.41 voor de steekproef, wat overeenkomt met een p-waarde van .19. Je rapporteert je resultaten:
“De gemiddelde dagelijkse calciuminname van de deelnemers verschilde niet van de aanbevolen hoeveelheid van 1000 mg, t(9) = 1.41, p = 0.19.”
Gepubliceerd op
9 augustus 2022
door
Shaun Turney.
Bijgewerkt op
29 januari 2024.
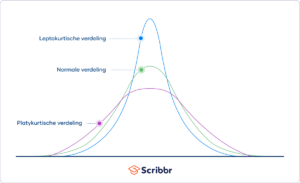
Kurtosis (welving) is een maat voor de staartvormigheid (tailedness) van een verdeling. De staartvorm geeft aan hoe vaak uitschieters (outliers) voorkomen. Excess kurtosis is de staartvorm van een verdeling ten opzichte van een normale verdeling.
Verdelingen met een gemiddelde kurtosis (gemiddelde staarten) zijn mesokurtisch (mesokurtic).
Verdelingen met een lage kurtosis (dunne staarten) zijn platykurtisch (platykurtic).
Verdelingen met een hoge kurtosis (dikke staarten) zijn leptokurtisch (leptokurtic).
Staarten (tails) zijn de taps toelopende uiteinden aan weerszijden van een verdeling. Staarten vertegenwoordigen de waarschijnlijkheid of frequentie van waarden die extreem hoog of laag zijn in vergelijking met het gemiddelde. De staarten geven dus aan hoe vaak uitschieters voorkomen.
Voorbeeld: Soorten kurtosis
Let opKurtosis en skewness (scheefheid) zijn beide belangrijke maten voor de vorm van een verdeling. Skewness zegt iets over de scheefheid (asymmetrie) van de verdeling, terwijl kurtosis iets zegt over de welving (staartdikte) van de verdeling.
Gepubliceerd op
8 augustus 2022
door
Shaun Turney.
Bijgewerkt op
19 oktober 2022.
De nulhypothese en alternatieve hypothese zijn twee tegengestelde beweringen waarvan onderzoekers met behulp van een statistische test de bewijzen tegen elkaar afwegen:
Nulhypothese (H0): Er is geen effect in de populatie.
Alternatieve hypothese (Ha of H1): Er is wel een effect in de populatie.
Met het effect wordt meestal het effect van de onafhankelijke variabele op de afhankelijke variabele bedoeld.
Gepubliceerd op
15 juli 2022
door
Shaun Turney.
Bijgewerkt op
8 maart 2023.
Een chi-kwadraattoets is een statistische toets voor categorische data. De toets wordt gebruikt om te bepalen of je nominale of ordinale data significant afwijken van wat je had verwacht. Er zijn twee belangrijke soorten chikwadraattoetsen:
De chi-kwadraattoets voor verdelingen (chi-square goodness of fit test) wordt gebruikt om te toetsen of de frequentieverdeling van een categorische variabele afwijkt van je verwachtingen.
De chi-kwadraattoets voor samenhang (chi-square test of independence) wordt gebruikt om te toetsen of twee categorische variabelen aan elkaar gerelateerd zijn. Deze toets wordt ook wel de onafhankelijkheidstoets genoemd.
Chi-kwadraat wordt vaak geschreven als Χ² (spreek uit als “gie-kwadraat”). Ook worden vaak de Engelse termen gebruikt. In dat geval spreek je het uit als “kai-square”.
Gepubliceerd op
14 juli 2022
door
Shaun Turney.
Bijgewerkt op
9 maart 2023.
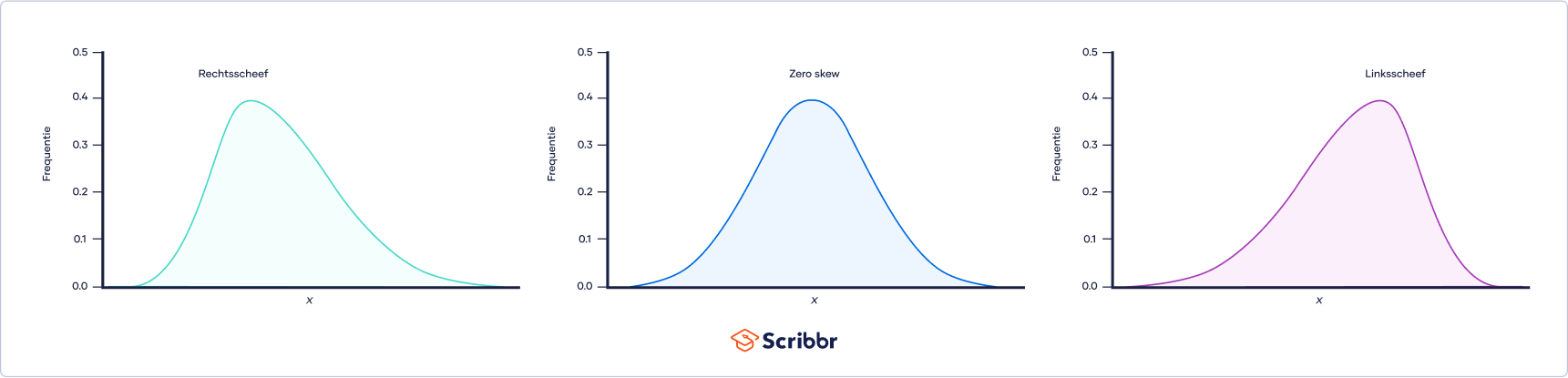
Skewness (scheefheid) is een maat voor de asymmetrie van een verdeling. Een verdeling is asymmetrisch als de linker- en rechterkant geen spiegelbeelden van elkaar zijn.
Een verdeling kan rechtse (positieve), linkse (negatieve) of nul scheefheid hebben. Dit wordt ook wel aangeduid als right skew, left skew en zero skew. Een rechtsscheve verdeling is langer aan de rechterkant van de piek en een linksscheve verdeling is langer aan de linkerkant van de piek:
Je kunt de skewness van een verdeling berekenen om:
Te bepalen of een variabele normaal verdeeld is. Een normale verdeling heeft zero skew, wat een voorwaarde is voor veel statistische toetsen.
Let opSkewness en kurtosis (welving) zijn beide belangrijke maten voor de vorm van een verdeling. Skewness zegt iets over de scheefheid (asymmetrie) van de verdeling, terwijl kurtosis iets zegt over de welving (staartdikte) van de verdeling.
 , is het aantal onafhankelijke stukjes informatie dat wordt gebruikt om een
, is het aantal onafhankelijke stukjes informatie dat wordt gebruikt om een