Gepubliceerd op
3 november 2021
door
Pritha Bhandari.
Bijgewerkt op
23 januari 2023.
De variantie (variance) is een maat die iets zegt over de spreiding in een dataset. Hoe meer de data verspreid zijn, hoe groter de variantie ten opzichte van het gemiddelde.
De variantie is een van de vier meest gebruikte spreidingsmaten (measures of variability), samen met:
Gepubliceerd op
2 november 2021
door
Pritha Bhandari.
Bijgewerkt op
21 april 2023.
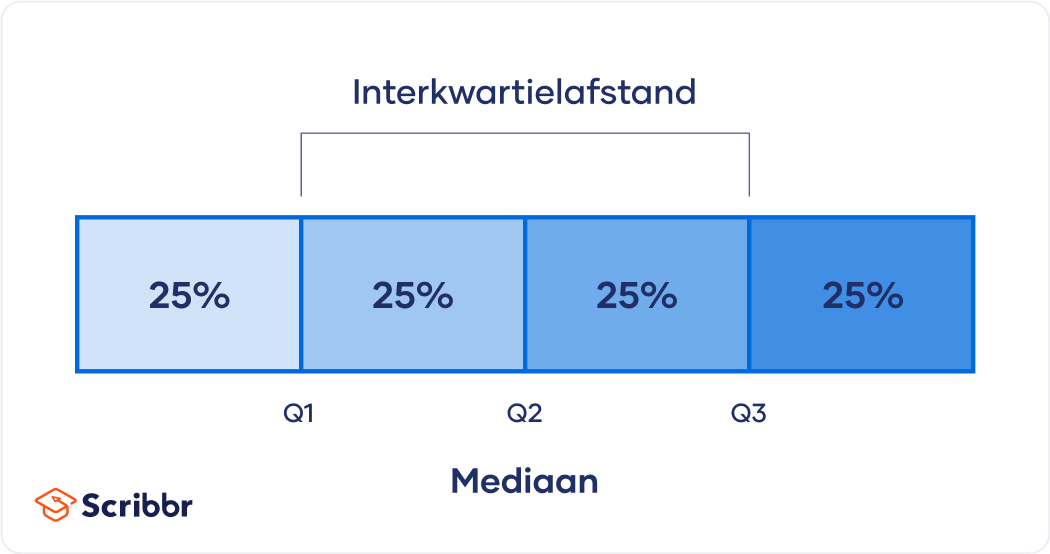
De interkwartielafstand (interquartile range) is een descriptieve statistiek die informatie geeft over de spreiding van de middelste helft van een verdeling. Deze maat behoort tot de vier meest gebruikte spreidingsmaten (measures of variability).
Iedere verdeling waarbij de waarden zijn gerangschikt van laag naar hoog kan worden verdeeld in vier gelijke delen (kwartielen). De interkwartielafstand (IQR) bevat het tweede en derde kwartiel, wat neerkomt op het middelste deel of de “middelste helft” van je dataset.
Het bereik (de range) geeft informatie over de spreiding in de gehele dataset, terwijl de interkwartielafstand gelijk is aan het bereik van de middelste helft.
Gepubliceerd op
2 november 2021
door
Pritha Bhandari.
Bijgewerkt op
10 februari 2023.
De spreiding geeft aan hoe ver datapunten van elkaar en van het centrum van een verdeling verwijderd zijn. Je gebruikt spreidingsmaten in combinatie met centrummaten om de data samen te vatten met beschrijvende statistieken.
Spreiding wordt ook wel variabiliteit genoemd. Meestal gebruik je een van de volgende spreidingsmaten (measures of variability):
Bereik (range): het verschil tussen de hoogste en laagste waarde.
Interkwartielafstand (interquartile range): het verschil tussen het eerste en derde kwartiel.
Gepubliceerd op
29 oktober 2021
door
Pritha Bhandari.
Bijgewerkt op
23 januari 2023.
Het bereik (ook wel spreidingsbreedte of range genoemd) is het interval tussen de laagste en de hoogste waarde in de dataset. Het is een veelgebruikte maat voor de spreiding (variability).
Het bereik wordt berekend door de laagste waarde van de hoogste waarde af te trekken. Als het bereik groot is, is er sprake van een hoge variabiliteit, terwijl een laag bereik gepaard gaat met een lage variabiliteit.
Gepubliceerd op
25 oktober 2021
door
Pritha Bhandari.
Bijgewerkt op
1 maart 2023.
De modus (mode) of modale waarde van een dataset is de waarde die het vaakst voorkomt. Het is een centrummaat die laat zien wat de meest populaire antwoordoptie of het meest voorkomende kenmerk is voor de steekproef.
Centrummaten vallen onder beschrijvende (descriptieve) statistiek en helpen je het midden (of centrum) van de dataset te vinden. De drie meest voorkomende centrummaten zijn de modus, mediaan (median) en het gemiddelde (mean).
Gepubliceerd op
22 oktober 2021
door
Pritha Bhandari.
Bijgewerkt op
23 januari 2023.
De mediaan (median) is de waarde die zich precies in het midden van een dataset bevindt als je de waarden van laag naar hoog zet. Het is een centrummaat die de laagste 50% van de waarden scheidt van de hoogste 50%.
De stappen om de mediaan te vinden zijn afhankelijk van het aantal waarden in de dataset. Bij een oneven aantal staat één waarde in het midden, maar bij een even aantal waarden moet je het gemiddelde van de twee middelste waarden berekenen om de mediaan te vinden.
De mediaan wordt meestal gebruikt voor kwantitatieve data (waarbij de waarden numeriek zijn), maar je kunt de mediaan soms ook gebruiken voor ordinale data (waarbij de waarden zijn verdeeld over categorieën).
Gepubliceerd op
21 oktober 2021
door
Pritha Bhandari.
Bijgewerkt op
23 januari 2023.
Het rekenkundig gemiddelde (mean) van een dataset is de som van alle waarden, gedeeld door het totale aantal waarden. Dit is de meest gebruikte centrummaat, gevolgd door de mediaan en modus.
Gepubliceerd op
21 oktober 2021
door
Pritha Bhandari.
Bijgewerkt op
24 augustus 2022.
Centrummaten (measures of central tendency) helpen je het midden of gemiddelde van een dataset te vinden. De drie meest voorkomende centrummaten zijn de modus (mode), mediaan (median) en het gemiddelde (mean).
Modus: de waarde die het vaakst voorkomt.
Mediaan: de middelste waarde als je de dataset van kleinste naar grootste waarde rangschikt.
Gemiddelde: de som van alle waarden, gedeeld door het totale aantal waarden.
Als je beschrijvende statistieken gebruikt om je data samen te vatten, kijk je niet alleen naar de centrale tendens (central tendency), maar ook naar de verdeling en spreiding of variabiliteit van je dataset.
Gepubliceerd op
19 oktober 2021
door
Pritha Bhandari.
Bijgewerkt op
9 januari 2023.
Met descriptieve of beschrijvende statistiek orden je de data en vat je de kenmerken van je dataset samen. Een dataset is een verzameling reacties of observaties van een steekproef of een hele populatie.
Bij kwantitatief onderzoek begin je aan je statistische analyse na afronding van de dataverzameling. Bij de eerste stap beschrijf je de kenmerken van de antwoorden, zoals het gemiddelde van een variabele (bijvoorbeeld leeftijd), of de relatie tussen twee variabelen (bijvoorbeeld tussen leeftijd en creativiteit).
Bij de volgende stap kijk je naar toetsende of inferentiële statistieken, die je helpen beslissen of de data je hypothese bevestigen en of het resultaat generaliseerbaar is naar een grotere populatie.
Gepubliceerd op
20 september 2021
door
Pritha Bhandari.
Bijgewerkt op
20 januari 2023.
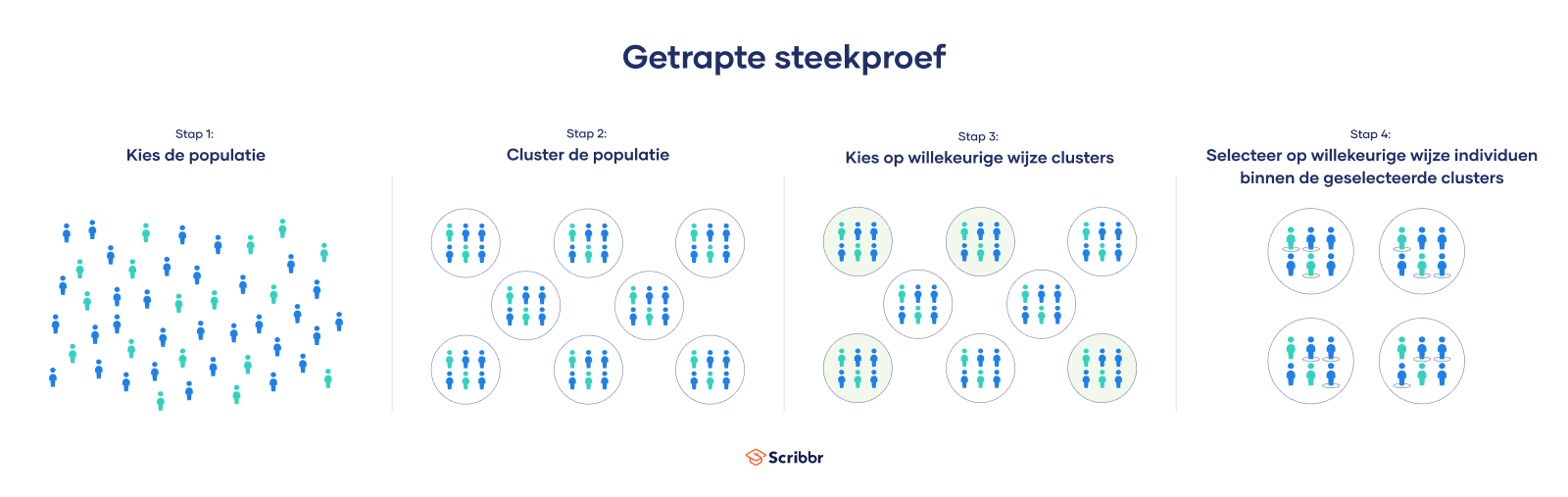
Bij getrapte steekproeven (ook wel multistage sampling of een meertrapssteekproef genoemd) trek je een steekproef uit een populatie, waarna je nog één of meerdere steekproeven trekt (met steeds kleinere eenheden in iedere fase).
Voorbeeld: Getrapte steekproefJe doet onderzoek naar de tevredenheid over gemeentebeleid. Je kunt niet alle inwoners van alle gemeenten een enquête aanbieden. Daarom trek je eerst een aselecte steekproef om enkele provincies te kiezen. Vervolgens trek je nog een steekproef om gemeenten te selecteren. Ten slotte trek je nog een laatste aselecte steekproef om 200 huishoudens uit die gemeenten te selecteren voor de enquête.