One-Way ANOVA | Interpretatie, Uitvoering & Voorbeelden
Een one-way ANOVA toetst of de groepsgemiddelden van twee of meer groepen significant van elkaar verschillen. Hierbij wordt gebruikgemaakt van één onafhankelijke variabele.
ANOVA, wat staat voor Analysis of Variance, is een overkoepelende term voor alle soorten ANOVAs. De meest bekende ANOVAs zijn de one-way ANOVA en de two-way ANOVA.
- Een one-way ANOVA gebruikt één onafhankelijke variabele.
- Een two-way ANOVA gebruikt twee onafhankelijke variabelen.
Je onafhankelijke variabele is het type kunstmest en je afhankelijke variabele is de gewasopbrengst.
Wanneer gebruik je een one-way ANOVA?
Je gebruikt een one-way ANOVA als je data hebt verzameld voor één categorische onafhankelijke variabele en één kwantitatieve afhankelijke variabele. De onafhankelijke variabele moet ten minste drie niveaus hebben (i.e., ten minste drie verschillende groepen of categorieën).
De ANOVA vertelt je of de afhankelijke variabele verandert als het niveau van de onafhankelijke variabele verandert. Bijvoorbeeld:
- Je onafhankelijke variabele is socialemediagebruik, en je verdeelt participanten over drie groepen met een laag, gemiddeld en hoog gebruiksniveau om te onderzoeken of er een verschil is in het aantal uren slaap per nacht.
- Je onafhankelijke variabele is het merk frisdrank, en je verzamelt data over Coca-Cola, Pepsi, Sprite en Fanta om uit te zoeken of er een verschil is in de prijs per 100 ml.
- Je onafhankelijke variabele is soort kunstmest, en je behandelt akkers met mengsels 1, 2 en 3 om uit te zoeken of er een verschil is in gewasopbrengst.
De nulhypothese (H0) van een ANOVA is dat er geen verschil is tussen de groepsgemiddelden. De alternatieve hypothese (Ha of H1) is dat ten minste één groep significant verschilt van het totale gemiddelde van de afhankelijke variabele.
Als je slechts twee groepen wilt vergelijken, kun je beter een t-toets gebruiken.
- Als je onafhankelijke variabele between-subjects varieert (alle participanten krijgen maar één van de condities aangeboden), gebruik je een ongepaarde t-test (independent t-test).
- Als je onafhankelijke variabele within-subjects varieert (alle participanten krijgen alle condities achter elkaar aangeboden), gebruik je een gepaarde t-test (dependent t-test).


Hoe werkt een ANOVA test?
Een ANOVA bepaalt of het verschil tussen de groepen van de onafhankelijke variabele (de niveaus) statistisch significant is door te berekenen of de gemiddelden van de groepen verschillen van het totale gemiddelde van de afhankelijke variabele.
Als één van de groepsgemiddelden significant verschilt van het totale gemiddelde, wordt de nulhypothese verworpen.
ANOVA gebruikt de F-test voor statistische significantie. Hierdoor kunnen meerdere gemiddelden tegelijkertijd worden vergeleken. Als je meerdere t-toetsen zou gebruiken voor de vergelijking van meer dan twee groepen, is er voor iedere t-toets een risico (meestal 5%) dat je een Type I-fout maakt. Door meerdere t-toetsen uit te voeren, stijgt het totale risico op een Type I-fout sterk. Dit gebeurt niet bij een ANOVA.
De F-test vergelijkt de variantie in elk groepsgemiddelde met de totale groepsvariantie. Als de variantie binnen groepen kleiner is dan de variantie tussen groepen, zal de F-test een hogere F-waarde vinden. Dit betekent dat er een grotere waarschijnlijkheid is dat het waargenomen verschil echt bestaat en dat de resultaten niet aan toeval te wijten zijn.
Aannames of assumpties voor een ANOVA
De aannames of assumpties voor een ANOVA komen grotendeels overeen met de algemene veronderstellingen van elke parametrische toets:
- Kwantitatieve, continue afhankelijke variabele: je afhankelijke variabele moet naast kwantitatief ook continu van aard zijn, wat betekent dat het interval- of ratio-metingen zijn. Dit betekent dat de afhankelijke variabele binnen het interval- of rationiveau iedere waarde aan kan nemen.
- Normaalverdeelde responsvariabele: de waarden van de afhankelijke variabele volgen een normale verdeling.
- Twee of meer categorische, onafhankelijke groepen: de onafhankelijke variabele moet uit twee of meer categorische, onafhankelijke groepen (niveaus) bestaan. Het is gebruikelijker om drie of meer groepen te hebben.
- Onafhankelijkheid van observaties: de data zijn verzameld met statistisch valide methoden, en er zijn geen verborgen relaties tussen de waarnemingen. Als je data niet aan deze aanname voldoen omdat je een confounding variabele (storende variabele) hebt waarvoor je moet controleren, gebruik je een ANOVA met blokkeringsvariabelen.
- Geen significante outliers: de aanwezigheid van outliers kan de validiteit van de resultaten van je one-way ANOVA aantasten.
- Homogeniteit van variantie: De variantie binnen elke groep die wordt vergeleken is voor elke groep gelijk. Als de varianties tussen de groepen verschillend zijn, is een ANOVA waarschijnlijk niet de juiste analyse voor de data.
One-way ANOVA uitvoeren
Hoewel je een ANOVA met de hand kunt uitvoeren, is het moeilijk om dat te doen met meer dan een paar waarnemingen. Hier zullen we laten zien hoe je een ANOVA analyse uitvoert met het statistische programma R, omdat het gratis, krachtig en overal beschikbaar is.
De voorbeelddataset voor het experiment over gewasopbrengst bevat data over:
- Soort kunstmest (type 1, 2 of 3)
- Plantdichtheid (1 = lage dichtheid, 2 = hoge dichtheid)
- Locatie van plant in het veld (blok 1, 2, 3 of 4)
- Uiteindelijke gewasopbrengst (in bushels per hectare)
- Fertilizer = kunstmest
- Yield = gewasopbrengst
- Density = (plant)dichtheid
- Block = blok (locatie van plant in het veld)
Dit geeft ons voldoende informatie om verschillende ANOVA-toetsen uit te voeren en te zien welk model het beste bij de data past.
Voor de one-way ANOVA zullen we alleen het effect van het soort kunstmest op de gewasopbrengst analyseren.
Nadat je de dataset in de R-omgeving hebt geladen, kun je het commando aov()gebruiken om een ANOVA uit te voeren. In dit voorbeeld worden de verschillen in het gemiddelde van de responsvariabele, gewasopbrengst, gemodelleerd als een functie van het type kunstmest.
one.way <- aov(yield ~ fertilizer, data = crop.data)
Resultaten ANOVA interpreteren
Om de samenvatting van een statistisch model in R te bekijken, gebruik je de functie summary().
summary(one.way)De samenvatting van een ANOVA in R ziet er als volgt uit:
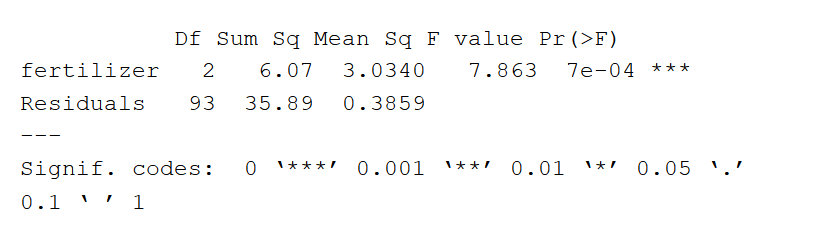
De ANOVA-output geeft een schatting van hoeveel variatie in de afhankelijke variabele door de onafhankelijke variabele kan worden verklaard.
- De eerste kolom vermeldt de onafhankelijke variabele samen met de modelresiduen (ook wel de modelfout genoemd).
- De kolom Df toont de vrijheidsgraden voor de onafhankelijke variabele (berekend door het aantal groepen in de variabele te nemen en daar 1 vanaf te halen), en de vrijheidsgraden voor de residuen (berekend door het totale aantal waarnemingen min 1 te nemen en daarvan het aantal groepen in elk van de onafhankelijke variabelen af te trekken).
- De kolom Sum Sq toont de som van de kwadraten (sum of squares, ook wel de totale variatie) tussen de groepsgemiddelden en het totale gemiddelde dat door die variabele wordt verklaard. De som van de kwadraten voor de variabele “kunstmest” is 6.07, terwijl de som van de residuen 35.89 is.
- De kolom Mean Sq is het gemiddelde van de som van de kwadraten, dat wordt berekend door de som van de kwadraten te delen door de vrijheidsgraden.
- De kolom F-value is de teststatistiek van de F-test: het gemiddelde kwadraat van elke onafhankelijke variabele gedeeld door het gemiddelde kwadraat van de residuen. Hoe groter de F-waarde, hoe waarschijnlijker het is dat de variantie die met de onafhankelijke variabele samenhangt, echt is en niet door toeval kan worden verklaard.
- De kolom Pr(>F) is de p-waarde van de F-statistiek. Hieruit blijkt hoe waarschijnlijk het is dat de met de test berekende F-waarde zou zijn opgetreden als de nulhypothese van geen verschil tussen de groepsgemiddelden waar was.
Omdat de p-waarde van de onafhankelijke variabele, kunstmest, significant is (p < 0.05), is het waarschijnlijk dat het soort kunstmest een significant effect heeft op de gemiddelde gewasopbrengst.
Post-hoc-analyse voor ANOVA
Een ANOVA vertelt je of er verschillen bestaan tussen de groepen van de onafhankelijke variabele, maar niet welke verschillen significant zijn. Om na te gaan hoe de groepen van elkaar verschillen, voer je een TukeyHSD (Tukey’s Honestly-Significant Difference) post-hoc-analyse uit.
TukeyHSD(one.way)De Tukey-test vergelijkt de groepen twee aan twee en gebruikt een voorzichtige (conservatieve) foutschatting om de groepen te vinden die statistisch van elkaar verschillen.
De output van de TukeyHSD ziet er als volgt uit:
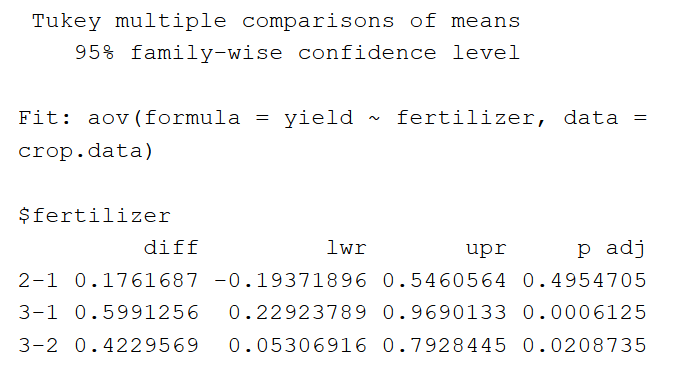
Eerst vermeldt de tabel het geteste model (“Fit”). Vervolgens worden de parallelle verschillen tussen de groepen voor de onafhankelijke variabele vermeld.
Onder “$fertilizer” zien we het gemiddelde verschil tussen elke kunstmestbehandeling (“diff”), de onder- en bovengrens van het 95%-betrouwbaarheidsinterval (“lwr” en “upr”), en de p-waarde, gecorrigeerd voor meervoudige paarsgewijze vergelijkingen.
Uit de paarsgewijze vergelijkingen blijkt dat kunstmest 3 een significant hogere gemiddelde opbrengst heeft dan zowel kunstmest 2 als kunstmest 1, maar dat het verschil tussen de gemiddelde opbrengst van kunstmest 2 en 1 niet statistisch significant is.
Resultaten ANOVA rapporteren
Bij het rapporteren van de resultaten van een ANOVA geef je een korte beschrijving van de variabelen die je hebt onderzocht, de F-waarde, vrijheidsgraden en p-waarden voor elke onafhankelijke variabelen, en leg je uit wat de resultaten betekenen.
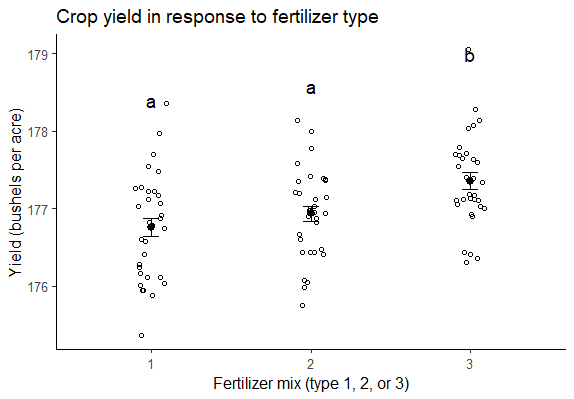
Als je meer gedetailleerde informatie wilt geven over de in je test gevonden verschillen, kun je ook een grafiek van je ANOVA-resultaten bijvoegen, met groepsletters boven elke groep van de onafhankelijke variabele om aan te geven welke groepen statistisch van elkaar verschillen:
Veelgestelde vragen over one-way ANOVA
Citeer dit Scribbr-artikel
Als je naar deze bron wilt verwijzen, kun je de bronvermelding kopiëren of op “Citeer dit Scribbr-artikel” klikken om de bronvermelding automatisch toe te voegen aan onze gratis Bronnengenerator.
Scharwächter, V. (2022, 02 september). One-Way ANOVA | Interpretatie, Uitvoering & Voorbeelden. Scribbr. Geraadpleegd op 14 april 2025, van https://www.scribbr.nl/statistiek/one-way-anova-uitgelegd/
