Hoe bepaal je het bereik (range) van een dataset? | Voorbeeld
Het bereik (ook wel spreidingsbreedte of range genoemd) is het interval tussen de laagste en de hoogste waarde in de dataset. Het is een veelgebruikte maat voor de spreiding (variability).
Je gebruikt spreidingsmaten en centrummaten om je data samen te vatten met behulp van descriptieve of beschrijvende statistieken.
Het bereik wordt berekend door de laagste waarde van de hoogste waarde af te trekken. Als het bereik groot is, is er sprake van een hoge variabiliteit, terwijl een laag bereik gepaard gaat met een lage variabiliteit.
Bereik berekenen
Je kunt het bereik met de hand berekenen of met behulp van onze bereik calculator hieronder.
Het bereik berekenen
Je gebruikt de volgende formule om het bereik te berekenen:
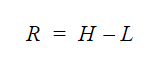
- R = range (bereik)
- H = hoogste waarde
- L = laagste waarde
Het bereik is de makkelijkst te berekenen spreidingsmaat. Om het bereik te bepalen, volg je de volgende stappen:
- Rangschik alle waarden in je dataset van laag naar hoog.
- Trek de laagste waarde van de hoogste waarde af.
Het stappenplan is hetzelfde voor positieve en negatieve waarden, en ook voor hele getallen of getallen met decimalen.
| Participant | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| Leeftijd | 37 | 19 | 31 | 29 | 21 | 26 | 33 | 36 |
Eerst rangschik je de waarden van laag naar hoog om de laagste waarde (L) en de hoogste waarde (H) te bepalen.
| Leeftijd | 19 | 21 | 26 | 29 | 31 | 33 | 36 | 37 |
|---|
Vervolgens bepaal je het bereik door de laagste waarde van de hoogste waarde af te trekken.
R = H – L
R = 37 – 19 = 18
Het bereik van de dataset is 18 jaar.
Hoe informatief is het bereik?
Het bereik is over het algemeen een goede indicator voor de spreiding als je een verdeling hebt zonder extreme waarden (uitbijters of outliers). Als je het bereik combineert met centrummaten (measures of central tendency), kan het bereik bijdragen aan het begrip van je dataset.
Het bereik kan misleidend zijn als je uitschieters in je dataset hebt. Slechts één extreme waarde in de dataset levert al een heel ander bereik op.
| Leeftijd | 19 | 21 | 26 | 29 | 31 | 33 | 36 | 61 |
|---|
Hoewel we dezelfde formule gebruiken, krijgen we dit keer een heel ander resultaat:
R = H – L
R = 61 – 19 = 42
Door de uitschieter is ons bereik nu 42 jaar.
In het bovenstaande voorbeeld suggereert het bereik veel meer spreiding dan in werkelijkheid het geval is. Hoewel we een groot bereik hebben, zijn de meeste waarden eigenlijk geclusterd rond een duidelijk midden.
Omdat er slechts twee getallen worden gebruikt om het bereik te berekenen, wordt deze maat al snel beïnvloed door uitbijters. Ook zegt het bereik niets over de vorm van de verdeling (normaal verdeeld of scheef verdeeld).
Om een duidelijk beeld te krijgen van de spreiding, kun je het bereik het beste gebruiken in combinatie met andere spreidingsmaten, zoals de interkwartielafstand en de standaarddeviatie.
Veelgestelde vragen
Citeer dit Scribbr-artikel
Als je naar deze bron wilt verwijzen, kun je de bronvermelding kopiëren of op “Citeer dit Scribbr-artikel” klikken om de bronvermelding automatisch toe te voegen aan onze gratis Bronnengenerator.
Merkus, J. (2021, 29 oktober). Hoe bepaal je het bereik (range) van een dataset? | Voorbeeld. Scribbr. Geraadpleegd op 6 april 2025, van https://www.scribbr.nl/statistiek/bereik/
